ETF-Investments und die damit verbundenen Volumina wachsen seit Jahren kontinuierlich. ETFs sind längst kein Ergänzungsprodukt mehr, sondern ein zentraler Bestandteil moderner Anlage- und Brokerage-Angebote – sowohl für Neobanken als auch für etablierte Banken und Broker.
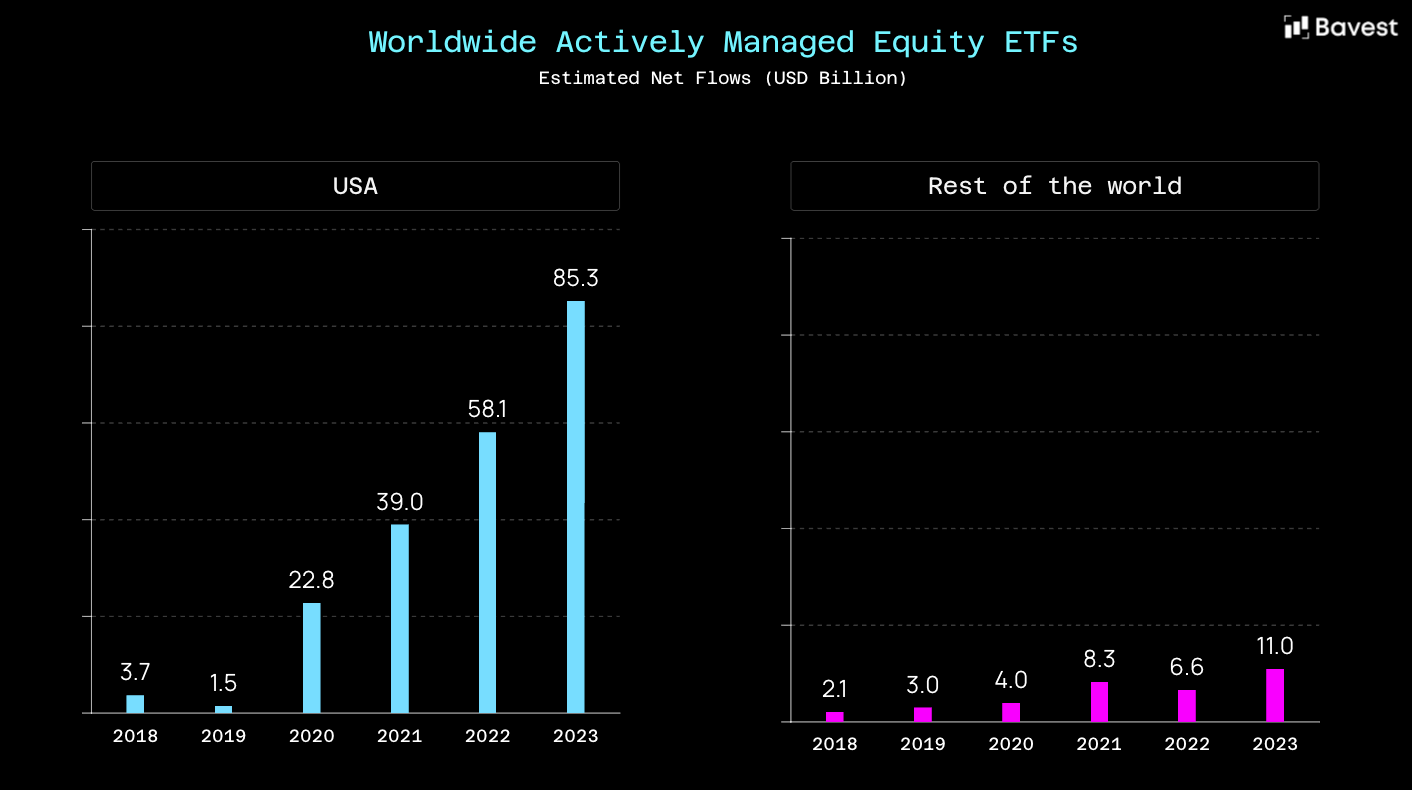
Mit diesem Wachstum steigen jedoch auch die Anforderungen an die zugrunde liegenden Daten. Die derzeit etablierten Datenanbieter können diese Anforderungen zunehmend nicht mehr erfüllen. Die Bereitstellung grundlegender Informationen wie Holdings oder grober Asset-Allokationen reicht für den operativen Einsatz nicht mehr aus.
Moderne Investmentplattformen müssen regulatorische Vorgaben erfüllen, Nutzern umfassende Transparenz bieten und sich gleichzeitig über datengetriebene Funktionen, Analysen und Tools differenzieren. Dafür benötigen sie konsistente, tief strukturierte und maschinenlesbare ETF-Daten, die sich direkt in produktive Systeme integrieren lassen.
Genau hier zeigt sich das strukturelle Problem des Marktes. Bevor wir auf Lösungsansätze eingehen, lohnt sich ein genauer Blick auf die Ursachen und Grenzen heutiger ETF-Datenmodelle.

Das strukturelle Versagen heutiger ETF-Datenanbieter zeigt sich nicht in einzelnen Fehlern, sondern entlang mehrerer grundlegender Dimensionen. Besonders deutlich wird dies in der Datenbreite, der Datentiefe, den analytischen Fähigkeiten sowie bei regulatorischen Anforderungen.
Viele etablierte Anbieter konzentrieren sich primär auf große, etablierte ETFs mit hohem verwaltetem Vermögen. Nischenprodukte, spezialisierte Strategien oder neu aufgelegte ETFs mit geringerem AuM werden entweder verspätet, unvollständig oder gar nicht erfasst.
Für moderne Investmentplattformen ist diese Einschränkung problematisch. Gerade thematische ETFs, spezialisierte Faktorprodukte oder regionale Nischenstrategien gewinnen an Bedeutung – sowohl für Privatanleger als auch für professionelle Nutzer. Eine Datenabdeckung, die sich faktisch auf einen Teil des Marktes beschränkt, wird den Anforderungen moderner Plattformen nicht mehr gerecht.
Selbst dort, wo ETFs grundsätzlich abgedeckt sind, fehlt es häufig an Tiefe und Konsistenz. Vollständige und aktuelle Holdings sind nicht immer verfügbar, einzelne Datenpunkte fehlen oder sind inkonsistent, historische Zeitreihen sind lückenhaft oder methodisch nicht sauber dokumentiert.
Diese Defizite haben unmittelbare operative Auswirkungen. Ohne verlässliche und vollständige Daten lassen sich weder fundierte Analysen noch stabile produktive Prozesse aufbauen. In der Praxis führt das dazu, dass Banken und Broker Daten manuell ergänzen, eigene Annahmen treffen oder mit vereinfachten Modellen arbeiten müssen – mit entsprechendem Risiko für Fehler und Inkonsistenzen.
Ein weiteres zentrales Defizit liegt im Bereich der Analyse. Viele Datenanbieter liefern primär beschreibende Informationen, jedoch kaum belastbare Analysen, die über einfache Kennzahlen hinausgehen.
Moderne Investmentplattformen benötigen jedoch deutlich mehr: Risikoanalysen, Kennzahlen wie Alpha und Beta, Volatilität, Korrelationen sowie eine Einordnung, ob ein ETF zum individuellen Investmentprofil eines Nutzers passt. Ohne diese analytische Ebene bleibt ETF-Investing oberflächlich und unterscheidet sich kaum zwischen einzelnen Plattformen.
Gerade hier liegt ein wesentlicher Differenzierungsfaktor. Wer ETFs aktiv in Produktlogik, Beratung oder Nutzererlebnis integrieren will, benötigt analytische Modelle, die Risiken, Strukturen und Profile systematisch bewerten – nicht nur Rohdaten.

Besonders deutlich zeigt sich die Überforderung bestehender Anbieter im regulatorischen Kontext. Anforderungen wie PRIIPs, MiFID II oder die Bereitstellung von KIDs und KIIDs in verschiedenen Sprachen sind heute keine Sonderfälle mehr, sondern operative Pflicht.
In der Praxis sind entsprechende Dokumente jedoch häufig nicht vollständig verfügbar, nicht aktuell oder nicht in allen relevanten Sprachen abrufbar. Die schiere Masse an ETFs, Jurisdiktionen und Dokumenten macht eine manuelle oder halbautomatisierte Erfassung kaum beherrschbar. Viele Anbieter sind strukturell nicht darauf ausgelegt, regulatorische Informationen in dieser Breite und Aktualität bereitzustellen.
Für Banken und Broker bedeutet das zusätzliche interne Prozesse, rechtliche Unsicherheit und einen hohen manuellen Aufwand – genau in einem Bereich, der eigentlich automatisiert und standardisiert sein müsste.
Der ETF-Markt wächst schneller, als etablierte Datenanbieter ihre Modelle und Systeme anpassen können. Produktvielfalt, regulatorische Anforderungen und der Wunsch nach datengetriebener Differenzierung stellen Anforderungen, die mit klassischen Datenansätzen nicht mehr abgedeckt werden.
Das Problem ist nicht punktuell, sondern strukturell. Und genau deshalb reicht es nicht aus, bestehende Modelle schrittweise zu erweitern. Es braucht einen grundlegend anderen Ansatz für ETF-Daten.

Die beschriebenen Defizite heutiger ETF-Datenanbieter lassen sich nicht durch punktuelle Erweiterungen oder zusätzliche Datenfeeds beheben. Sie sind struktureller Natur und erfordern einen grundlegend anderen Ansatz in der Datenbeschaffung, -verarbeitung und -qualitätskontrolle.
Bavest wurde genau mit diesem Anspruch entwickelt. Statt sich auf statische Datenlieferungen zu stützen, basiert die Dateninfrastruktur auf einer automatisierten, KI-gestützten Beschaffung aus öffentlich verfügbaren Primärquellen wie Emittentenunterlagen, regulatorischen Dokumenten, Fondsreports und weiteren strukturierten wie unstrukturierten Quellen. Dadurch ist es möglich, auch Nischenprodukte, neu aufgelegte ETFs oder spezialisierte ETPs zeitnah und vollständig abzudecken – unabhängig von ihrer Größe oder ihrem verwalteten Vermögen.
Die gesammelten Rohdaten werden über eine vollständig automatisierte Datenpipeline verarbeitet, normalisiert und validiert. Eigene Systeme zur Datenkonsistenz- und Plausibilitätsprüfung stellen sicher, dass Daten nicht nur vollständig, sondern auch korrekt und methodisch konsistent vorliegen. Fehler, Ausreißer oder Inkonsistenzen werden systematisch erkannt und adressiert, bevor die Daten produktiv genutzt werden.
Ergänzend dazu setzt Bavest auf interne Frameworks zur kontinuierlichen Qualitätskontrolle. Stichprobenbasierte Prüfmechanismen, regelbasierte Validierungen und laufende Re-Evaluationen stellen sicher, dass Datenqualität kein einmaliger Zustand, sondern ein fortlaufender Prozess ist. Dieser Ansatz erlaubt es, ETF-Daten in einer Tiefe und Verlässlichkeit bereitzustellen, die für regulatorische, analytische und produktive Anwendungsfälle notwendig ist.
Auf dieser Basis können nicht nur klassische Kennzahlen geliefert werden, sondern auch weiterführende Analysen. Risiko- und Performancekennzahlen, Faktor-Exposures sowie analytische Modelle zur Einordnung von ETFs in unterschiedliche Investment- und Risikoprofile werden systematisch berechnet und bereitgestellt. Damit wird ETF-Investing von einer rein beschreibenden Darstellung hin zu einer analytisch fundierten Nutzung weiterentwickelt.

Die praktische Relevanz dieses Ansatzes zeigt sich im Einsatz bei großen, international skalierenden Investmentplattformen. eToro nutzt die ETF-Daten und Analytics von Bavest als zentrale Datenbasis für den Ausbau seines ETF- und ETP-Angebots.
Durch die Integration der Bavest-API konnte eToro die Abdeckung seines ETF-Universums signifikant erweitern und gleichzeitig auf eine tiefere Daten- und Analyseebene zugreifen, die mit klassischen Anbietern nur mit erheblichem Integrations- und Kostenaufwand möglich gewesen wäre. Neben einer breiteren Produktabdeckung stehen insbesondere strukturierte Risiko- und Analysekennzahlen im Fokus, die für Transparenz, Vergleichbarkeit und datengetriebene Produktfunktionen entscheidend sind. Zudem konnte eToro mittels der Bavest API neue Features entwickeln, wie einen globalen ETF Screener, der Nutzern ermöglicht, alle ETFs die innerhalb von eToro angeboten werden, zu analysieren und zu filtern.
Die Nutzung einer einheitlichen, konsolidierten Dateninfrastruktur ermöglicht es eToro, neue Funktionen schneller zu entwickeln, analytische Features konsistent über Regionen hinweg auszurollen und regulatorische Anforderungen effizient umzusetzen. Gleichzeitig reduziert sich die Abhängigkeit von fragmentierten Datenquellen und komplexen Vendor-Setups, was operative Komplexität und laufende Kosten senkt.
Für eToro fungiert Bavest damit nicht als reiner Datenlieferant, sondern als infrastrukturelle Grundlage für skalierbare ETF-Produkte, analytische Mehrwerte und eine differenzierte Nutzererfahrung.
Der ETF-Markt wird weiter wachsen, und mit ihm die Anforderungen an Datenqualität und -struktur. Gleichzeitig steigt der Automatisierungsgrad in Brokerage- und Investmentplattformen. In diesem Umfeld reicht es nicht aus, Daten lediglich bereitzustellen.
Datenprovider tragen die Verantwortung, Informationen korrekt, konsistent und in einer Struktur bereitzustellen, die moderne operative, analytische und regulatorische Anwendungsfälle unterstützt. Manuelle Korrekturen auf Kundenseite dürfen dabei nicht zum Regelfall werden, sondern müssen die Ausnahme bleiben.
Bavest gehört global zu den wenigen Anbietern, die für nahezu das gesamte ETP-Universum nicht nur klassische Produkt- und Holdingsdaten, sondern auch strukturierte quantitative Kennzahlen wie Beta, Alpha sowie relevante regulatorische Informationen in konsistenter Form bereitstellen.
ETF-Daten sind kein statisches Informationsprodukt mehr. Sie sind eine zentrale operative Grundlage moderner Investmentplattformen.
Wenn ETF-Daten regelmäßig manuell korrigiert werden müssen, ist das ein strukturelles Versagen der Datenbereitstellung. Die Lösung liegt nicht in mehr internen Workarounds, sondern in besseren, tiefer strukturierten Datenmodellen.
Bavest verfolgt genau diesen Ansatz: ETF-Daten nicht als Rohmaterial, sondern als verlässliche, entscheidungsfähige Dateninfrastruktur bereitzustellen.
blog
