ETF investments and the associated volumes have been growing steadily for years. ETFs are no longer a supplementary product, but a central component of modern investment and brokerage offerings — both for neo-banks and established banks and brokers.
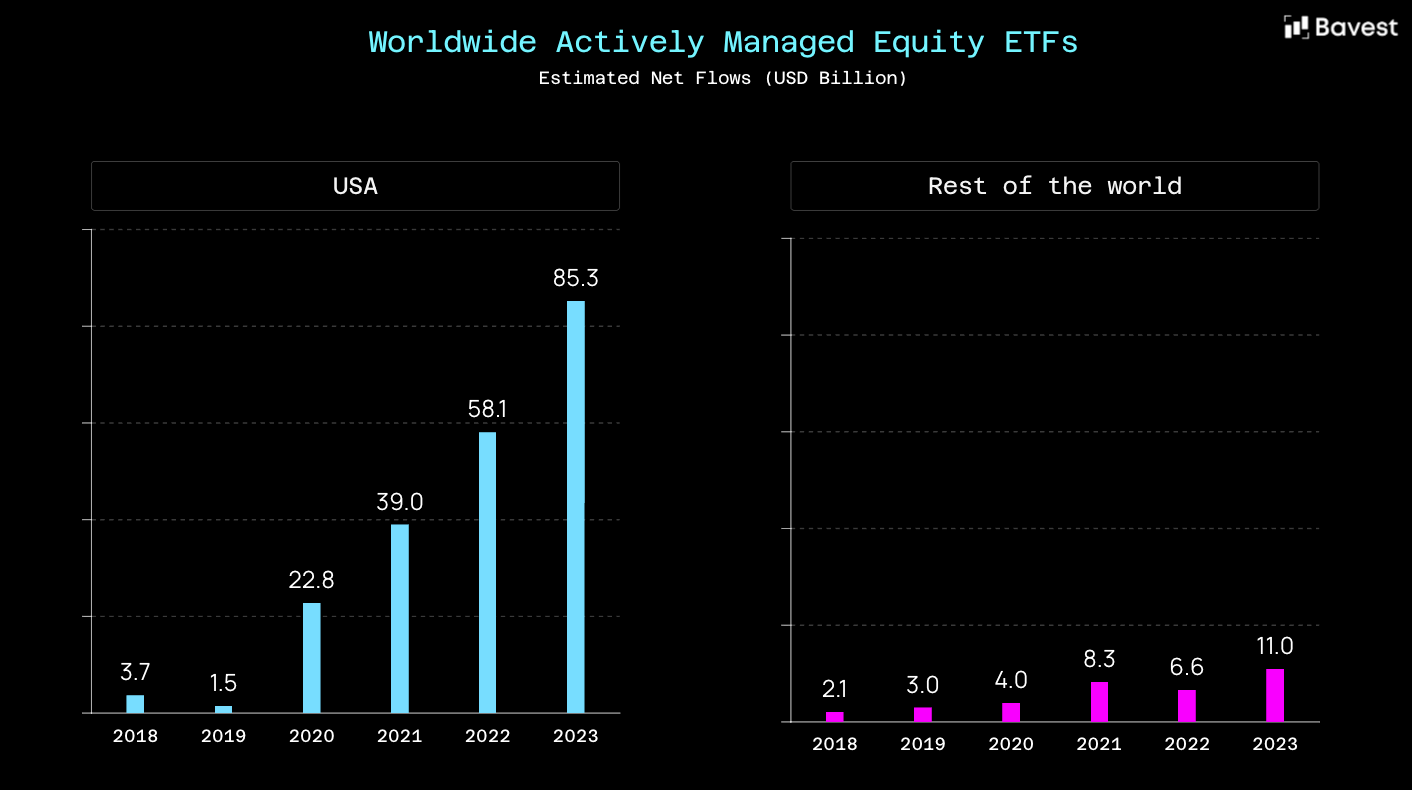
However, as this growth increases, so do the requirements for the underlying data. The currently established data providers are increasingly unable to meet these requirements. The provision of basic information such as holdings or rough asset allocations is no longer sufficient for operational use.
Modern investment platforms must meet regulatory requirements, offer users comprehensive transparency and at the same time differentiate themselves through data-driven functions, analyses and tools. To do this, they need consistent, deeply structured and machine-readable ETF data that can be directly integrated into productive systems.
This is precisely where the structural problem of the market emerges. Before we go into possible solutions, it's worth taking a closer look at the causes and limitations of today's ETF data models.

The structural failure of today's ETF data providers is not reflected in individual errors, but across several fundamental dimensions. This is particularly evident in the breadth of data, the depth of data, the analytical capabilities and regulatory requirements.
Many established providers focus primarily on large, established ETFs with high levels of assets under management. Niche products, specialized strategies or newly launched ETFs with lower AuM are either recorded late, incomplete, or not at all.
For modern investment platforms, this restriction is problematic. In particular, thematic ETFs, specialized factor products and regional niche strategies are gaining in importance — both for private investors and for professional users. Data coverage that is in fact limited to a part of the market no longer meets the requirements of modern platforms.
Even where ETFs are generally covered, there is often a lack of depth and consistency. Complete and current holdings are not always available, individual data points are missing or are inconsistent, historical time series are incomplete or not properly documented methodically.
These deficiencies have immediate operational effects. Without reliable and complete data, neither well-founded analyses nor stable productive processes can be set up. In practice, this means that banks and brokers have to manually add data, make their own assumptions or work with simplified models — with a corresponding risk of errors and inconsistencies.
Another key deficit lies in the area of analysis. Many data providers primarily provide descriptive information, but hardly any reliable analyses that go beyond simple key figures.
However, modern investment platforms require significantly more: risk analyses, key figures such as alpha and beta, volatility, correlations and a classification of whether an ETF fits a user's individual investment profile. Without this level of analysis, ETF investing remains superficial and barely differs between individual platforms.
This is precisely where an important differentiating factor lies. If you want to actively integrate ETFs into product logic, advice or user experience, you need analytical models that systematically evaluate risks, structures and profiles — not just raw data.

The overburden of existing providers is particularly evident in the regulatory context. Requirements such as PRIIPs, MiFID II or the provision of KIDs and KIIDs in various languages are no longer special cases, but operational obligations.
In practice, however, relevant documents are often not completely available, not up to date or not available in all relevant languages. The sheer mass of ETFs, jurisdictions and documents makes manual or semi-automated entry barely manageable. Many providers are structurally not designed to provide this breadth and timeliness of regulatory information.
For banks and brokers, this means additional internal processes, legal uncertainty and a high level of manual effort — precisely in an area that should actually be automated and standardized.
The ETF market is growing faster than established data providers can adapt their models and systems. Product diversity, regulatory requirements and the desire for data-driven differentiation pose requirements that are no longer covered by traditional data approaches.
The problem is not selective but structural. And that is precisely why it is not enough to gradually expand existing models. A fundamentally different approach to ETF data is needed.

The described deficiencies of today's ETF data providers cannot be remedied by selective expansions or additional data feeds. They are structural in nature and require a fundamentally different approach to data collection, processing, and quality control.
Bavest was developed precisely with this aim in mind. Instead of relying on static data deliveries, the data infrastructure is based on automated, AI-supported procurement from publicly available primary sources such as issuer documents, regulatory documents, fund reports and other structured and unstructured sources. This makes it possible to cover niche products, newly launched ETFs or specialized ETPs promptly and completely — regardless of their size or assets under management.
The raw data collected is processed, normalized and validated via a fully automated data pipeline. Our own systems for data consistency and plausibility checks ensure that data is not only complete, but also correct and methodically consistent. Errors, outliers, or inconsistencies are systematically identified and addressed before the data is used productively.
In addition, Bavest uses internal frameworks for continuous quality control. Samply-based verification mechanisms, rule-based validations and ongoing re-evaluations ensure that data quality is not a unique situation, but an ongoing process. This approach makes it possible to provide ETF data with the depth and reliability that is necessary for regulatory, analytical and productive use cases.
On this basis, not only classic key figures can be delivered, but also further analyses. Risk and performance indicators, factor exposures and analytical models for classifying ETFs into different investment and risk profiles are systematically calculated and provided. In this way, ETF investing is being developed from a purely descriptive presentation to an analytically based use.

The practical relevance of this approach is evident when used by large, internationally scaling investment platforms. eToro uses Bavest's ETF data and analytics as a central database for expanding its ETF and ETP offering.
By integrating the Bavest API, eToro was able to significantly expand the coverage of its ETF universe and at the same time access a deeper level of data and analysis that would only have been possible with traditional providers with considerable integration and costs. In addition to wider product coverage, the focus is in particular on structured risk and analysis indicators, which are decisive for transparency, comparability and data-driven product functions. eToro was also able to develop new features using the Bavest API, such as a global ETF screener, which enables users to analyze and filter all ETFs offered within eToro.
The use of a uniform, consolidated data infrastructure enables eToro to develop new functions faster, roll out analytical features consistently across regions, and efficiently implement regulatory requirements. At the same time, dependency on fragmented data sources and complex vendor setups is reduced, which reduces operational complexity and ongoing costs.
For eToro, Bavest does not simply act as a data provider, but as an infrastructural basis for scalable ETF products, analytical added value and a differentiated user experience.
The ETF market will continue to grow, and with it the requirements for data quality and structure. At the same time, the level of automation in brokerage and investment platforms is increasing. In this environment, simply providing data is not enough.
Data providers have the responsibility to provide information correctly, consistently, and in a structure that supports modern operational, analytical, and regulatory use cases. Manual corrections on the customer side must not become the norm, but must remain the exception.
Bavest is one of the few providers globally who provide not only classic product and holding data, but also structured quantitative indicators such as beta, alpha and relevant regulatory information in a consistent form for almost the entire ETP universe.
ETF data is no longer a static information product. They are a central operational basis for modern investment platforms.
If ETF data has to be corrected manually on a regular basis, this is a structural failure in data provision. The solution lies not in more internal workarounds, but in better, more deeply structured data models.
Bavest follows exactly this approach: providing ETF data not as raw material, but as a reliable, decision-making data infrastructure.
blog
